4 Data Frames
Un data frame è una versione bidimensionale di una lista (è a tutti gli effetti una speciale classe di lista).
Un data frame appresenta il modo ideale per salvare un intero mazzo di carte (e non solo). Si può pensare a un data frame come l’equivalente di una tabella di Excel. Un data frame raggruppa un insieme di vettori in una tabella bidimensionale. Ogni vettore diventa una colonna della tabella. Il risultato è che ogni colonna può contenere un tipo diverso di dato ma ogni elemento della colonna deve obbligatoriamente avere lo stesso tipo di dato:
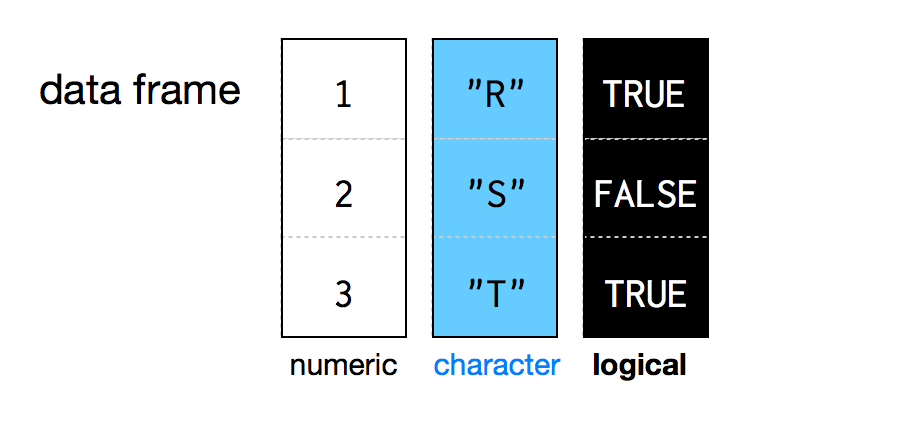
(#fig:data-frame )Un data frame
Creare un data frame dal nulla significa scrivere molto codice quindi non è consigliabile. Tuttavia, si può fare attraverso la funzione data.frame().
Dando in input alla funzione data.frame() dei vettori separati da virgole si otterrà un data frame. Occorre però dare dei nomi a questi vettori, il nome viene assegnato attraverso l’operatore =.
df <- data.frame(
figura = c("asso", "due", "sei"),
seme = c("picche", "picche", "picche"),
valore = c(1, 2, 3)
)
df## figura seme valore
## 1 asso picche 1
## 2 due picche 2
## 3 sei picche 3Bisogna assicurarsi che ogni vettore abbia la stessa lunghezza altrimenti R userà la tecnica di recycling affinchè le colonne del data frame abbiano la stessa lunghezza.
I nomi ( names ) delle colonne possono essere assegnati anche successivamente alla creazione del data frame usando la funzione names(), già vista in nomi e dimensioni.
Attraverso la funzione str() possiamo vedere quali oggetti sono stati raggruppati per creare il data frame.
str(df)## 'data.frame': 3 obs. of 3 variables:
## $ figura: chr "asso" "due" "sei"
## $ seme : chr "picche" "picche" "picche"
## $ valore: num 1 2 3stringsAsFactors = FALSE nella funzione data.frame().
:::
df <- data.frame(
figura = c("asso", "due", "sei"),
seme = c("picche", "picche", "picche"),
valore = c(1, 2, 3),
stringsAsFactors = FALSE
)
str(df)## 'data.frame': 3 obs. of 3 variables:
## $ figura: chr "asso" "due" "sei"
## $ seme : chr "picche" "picche" "picche"
## $ valore: num 1 2 3NA
In R i valori mancanti sono indicati come NA.
Ora potremmo finalmente creare il nostro mazzo di carte!
Ogni riga del nostro data frame deck potrebbe essere una carta da gioco, ogni colonna contiene le caratteristiche della carta, come figura, seme e valore. Il risultato finale è un oggetto come questo:
## figura seme valore
## re picche 13
## regina picche 12
## jack picche 11
## dieci picche 10
## nove picche 9
## otto picche 8
## sette picche 7
## sei picche 6
## cinque picche 5
## quattro picche 4
## ... Ma quanto dovremmo scrivere? Probabilmente troppo!
Scrivere del codice comporta fare degli errori di sintassi o di ortografia, per non parlare del consumo di tempo.
Fortunatamente R ci permette di importare grandi quantità di dati provenienti da diversi tipi di file e fonti come ad esempio i database o i file di testo.
Vediamo come importare in R i dati dal file “deck.csv” che contiene il nostro mazzo di 52 carte senza errori.
4.1 Importazione
Per importare un insieme di dati in R esistono diverse procedure.
deck.csv è un file comma-separated-values, o CSV in breve e contiene il seguente testo:
"figura","seme,"valore"
"king","picche",13
"queen","picche,12
"jack","picche,11
"ten","picche,10
"nove","picche,9
... Per importare un file di testo cliccare sull’icona Import Dataset in RStudio mostrata in Figura. Poi si selezioni From text file e il nome del file da importare (deck.csv, in questo caso).

(#fig:import )Importare un file
wizard
L’interfaccia di importazione, così come le altre procedure di R che permettono l’esecuzione di comandi in modo “code-free”m si chiama wizard. Cercheremo di ridurre al minimo l’uso degli wizard facendo prevalere quello dello script. Lo script ci permette di ricordare tutte le operazioni che sono state effettuate e replicarle con il minimo sforzo.
Se l’importazione avviene tramite lo wizard si può decidere quale nome dare al data frame che si sta importando insieme a tutte le caratteristiche dei dati (separatore decimale, tipo della colonna ecc…).
Figure 4.1: Wizard di importazione
Quando tutte le impostazioni sono state selezionate, cliccare su Import. R aprirà una nuova tabella, chiamata tab View che mostrerà il nuovo dataframe.
Figure 4.2: Tab view
read().
In particolare, esistono diversi tipi di lettura a seconda del tipo di file da importare. Per il momento ci limiteremo all’utilizzo della funzione read.csv().
:::
L’equivalente dell’operazione precedente è il comando seguente:
deck <- read.csv("data/deck.csv", #la posizione del file
sep = ',', #separatore delle colonne
header = TRUE, #la prima riga contiene le intestazioni di colonna
na.strings = ".", #come vengono indicati i dati mancanti nel file
stringsAsFactors = FALSE) #non voglio che le variabili character vengano convertite in fattoriPer visualizzare le prime righe e le ultime righe del data frame si possono usare rispettivamente le funzioni head() e tail().
head(deck, 10) #mostra le prime 10 righe## figura seme valore
## 1 re picche 13
## 2 regina picche 12
## 3 jack picche 11
## 4 dieci picche 10
## 5 nove picche 9
## 6 otto picche 8
## 7 sette picche 7
## 8 sei picche 6
## 9 cinque picche 5
## 10 quattro picche 4tail(deck) #mostra le ultime 5 righe## figura seme valore
## 47 sei cuori 6
## 48 cinque cuori 5
## 49 quattro cuori 4
## 50 tre cuori 3
## 51 due cuori 2
## 52 asso cuori 1Esercizio 10
Crare un nuovo data frame deckNA assegnandogli i dati contenuti in “deckNA.csv” specificando come vengono indicati i valori mancanti nel file. Assicurarsi che ogni colonna sia del tipo giusto e eventualmente convertire. Mostrare le prime 2 righe del dataframe deckNA.
deckNA <- read.csv("data/deckNA.csv", #la posizione del file
sep = ';', #separatore delle colonne
header = FALSE, #la prima riga contiene le intestazioni di colonna
na.strings = "na", #come vengono indicati i dati mancanti nel file
stringsAsFactors = FALSE) #non voglio che le variabili qualitative vengano convertite in fattori## Warning in read.table(file = file, header = header, sep
## = sep, quote = quote, : incomplete final line found by
## readTableHeader on 'data/deckNA.csv'head(deckNA,2)## V1 V2 V3
## 1 ace spades 14
## 2 king spades 134.2 Indicizzazione e subsetting
La notazione di R per estrarre elementi da un oggetto che sia un vettore, una matrice, un array o un data frame consiste nel scrivere il nome dell’oggetto seguito dalle parentesi quadre: df[ ].
All’interno delle parentesi andrà indicato l’indice (o gli indici per gli elementi n-dimensionali) che indicherà quale dimensione andare a indicizzare e con quale indice.
Gli indici sono dei vettori atomici (ricordiamo che uno scalare è un vettore atomico di un elemento) e possono essere di tipo intero, logico o stringa a seconda di che oggetto sto indicizzando. La seguente tabella riassume alcuni tipi di indicizzazione.
| oggetto | indicizzazione | tipo indice | risultato |
|---|---|---|---|
vettore
|
vettore[i]
|
integer, logical |
gli elementi di vettore alle posizioni i
|
matrice (o dataframe)
|
matrice[r,c]
|
integer, logical |
gli elementi di matrice nelle righe r e colonne c
|
matrice[r,]
|
integer, logical |
gli elementi di matrice nelle righe r
|
|
matrice[,c] o matrice[c]
|
integer, logical |
gli elementi di matrice nelle colonne c
|
|
dataframe
|
dataframe$var o dataframe["var"] o dataframe[["var"]]
|
character |
gli elementi di dataframe della colonna con nome "var"
|
lista
|
lista[[i]]
|
integer, logical |
gli oggetti di lista alle posizioni i
|
lista[["var"]]
|
character |
gli oggetti di lista alle posizioni con nome "var"
|
Hli indici iniziano da 1
In R, il primo elemento di un vettore avrà indice 1.
Un esempio visivo di indicizzazione su un vettore e su una matrice:
Figure 4.3: Indicizzazione
Se il nostro oggetto possiede l’attributo names possiamo indicizzarlo attraverso delle stringhe.
deck[1, c("figura", "seme", "valore")] # tutte le colonne## figura seme valore
## 1 re picche 13deck[, "valore"] # la colonna con nome "valore"## [1] 13 12 11 10 9 8 7 6 5 4 3 2 1 13 12 11 10
## [18] 9 8 7 6 5 4 3 2 1 13 12 11 10 9 8 7 6
## [35] 5 4 3 2 1 13 12 11 10 9 8 7 6 5 4 3 2
## [52] 1Gli indici interi possono essere anche negativi, in questo caso R darà come risultato gli elementi che NON sono nella posizione indicata dall’indice. Ad esempio, vettore[-2] restituirà tutti gli elementi di vettore tranne il secondo.
Il subsetting con i vettori logici è molto utile quando si vogliono filtrare degli oggetti usando delle condizioni (o funzioni di confronto).
Alcuni esempi di subsetting logico sono:
deck[1, c(TRUE, TRUE, FALSE)]## figura seme
## 1 re piccherows <- c(TRUE, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F,
F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F, F,
F, F, F, F, F, F, F, F, F, F, F, F, F, F)
deck[rows, ]## figura seme valore
## 1 re picche 13deck[deck$seme %in% c("cuori","picche"), ]## figura seme valore
## 1 re picche 13
## 2 regina picche 12
## 3 jack picche 11
## 4 dieci picche 10
## 5 nove picche 9
## 6 otto picche 8
## 7 sette picche 7
## 8 sei picche 6
## 9 cinque picche 5
## 10 quattro picche 4
## 11 tre picche 3
## 12 due picche 2
## 13 asso picche 1
## 40 re cuori 13
## 41 regina cuori 12
## 42 jack cuori 11
## 43 dieci cuori 10
## 44 nove cuori 9
## 45 otto cuori 8
## 46 sette cuori 7
## 47 sei cuori 6
## 48 cinque cuori 5
## 49 quattro cuori 4
## 50 tre cuori 3
## 51 due cuori 2
## 52 asso cuori 1Torneremo su questo argomento nel capitolo successivo subsetting logico.
4.3 Salvare in un file
Prima di continuare a lavorare sul nostro dataframe, salviamolo in un file .csv.
Per salvare un file in formato csv bisogna usare il comando write.csv().
write.csv(deck, #dataframe da salvare
file = "deckSalvato.csv", #nome del file
row.names = FALSE) #scrivere i nomi delle righe nel file Ora abbiamo un mazzo di carte virtuale!
La prossima lezione proveremo a modificare gli elementi di questo data frame usando le funzioni di R.